
Web scraping has emerged as an essential technique for gathering vast amounts of data from websites, making it a powerful tool for businesses and researchers alike. Through effective web data extraction, users can automate the process of collecting information, which can then be analyzed for various purposes, such as market research or trend analysis. With the rise of numerous web scraping tools available, individuals can quickly learn how to start scraping content online with minimal coding knowledge. By utilizing these tools, one can efficiently scrape websites to gather publicly available information, saving both time and resources in the process. As demand for data-driven insights continues to grow, understanding the intricacies of web scraping will become increasingly valuable in a digital-first world.
Data collection from the internet, often referred to as content harvesting or online extraction, is transforming how organizations conduct research and analysis. This practice allows users to effectively pull in information from various digital sources, enabling them to spot trends and make informed decisions. Many people are turning to data scraping methods to acquire valuable insights without manually sifting through countless pages of content. As businesses recognize the importance of harnessing online information, mastering various extraction techniques has never been more crucial. With an ever-growing array of tools designed for scraping content online, users can now effortlessly access a wealth of information that was once time-consuming to gather.
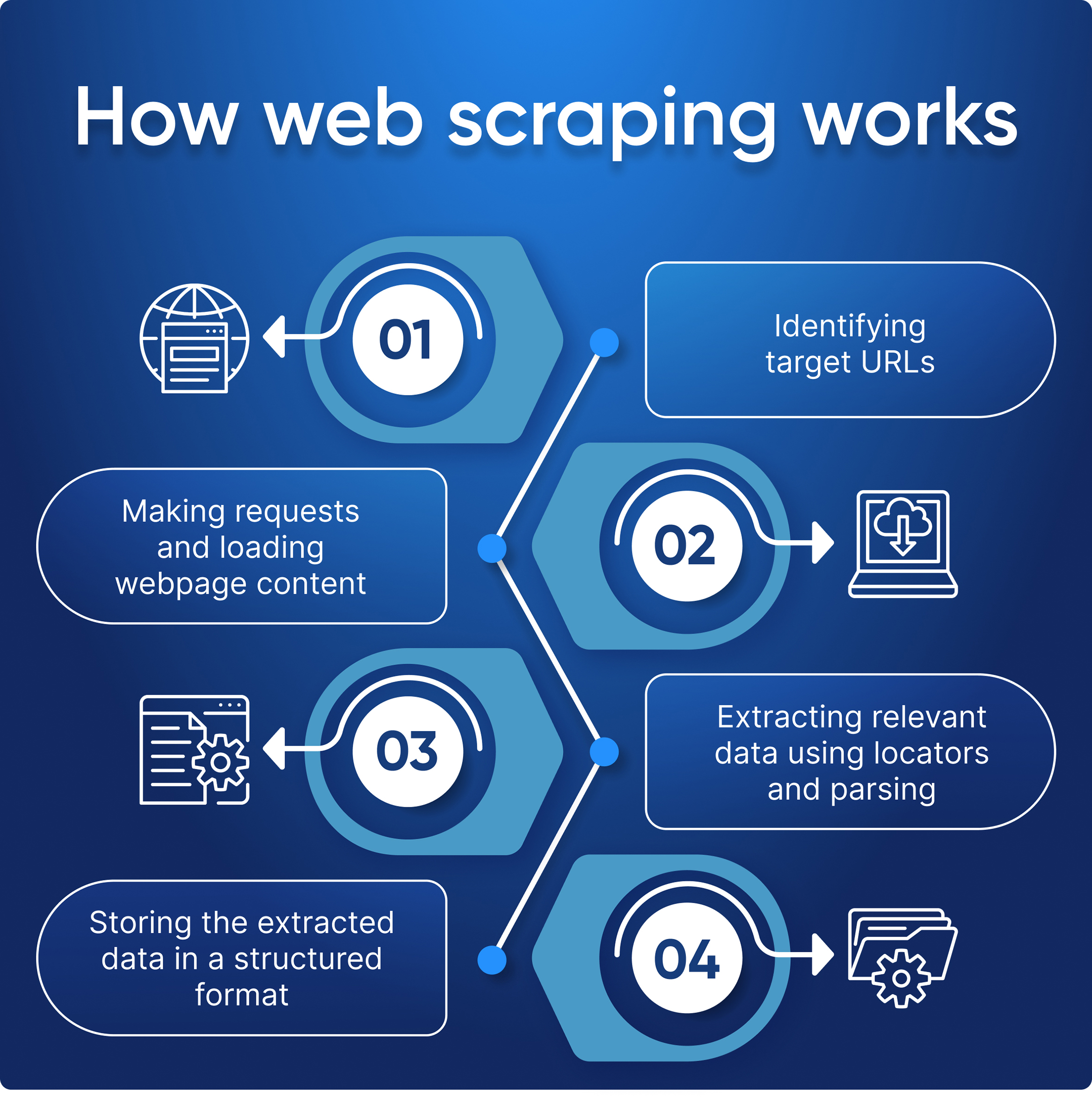
Understanding Web Scraping Techniques
Web scraping is a powerful technique used to extract data from websites in an automated manner. This process enables businesses and individuals to gather large amounts of data quickly and efficiently without the need for manual collection. By utilizing web scraping tools, it is possible to access and collect information from multiple web pages simultaneously, thereby saving both time and resources.
While web scraping can be advantageous, it is essential to understand the ethical implications of this practice. Many websites have specific terms of service regarding direct scraping of their content, and it’s important to respect those guidelines to avoid legal issues. Successful web data extraction requires careful planning and consideration of the targeted websites’ policies.
There are various methods for scraping websites, including employing libraries and frameworks that simplify the process. For instance, tools like Beautiful Soup, Scrapy, or Selenium offer functionalities to easily navigate HTML documents and extract relevant data. Understanding HTML structure and having programming skills are crucial for effectively utilizing these tools, as they allow for customized data scraping and content extraction.
In addition to programming knowledge, optimizing your web scraping activity for performance is critical. By scheduling scraping tasks during off-peak hours or using techniques like caching and throttling, you can minimize server load and achieve more efficient data collection. Learning the best practices of data scraping is vital for any application aiming to leverage web data.
Best Web Scraping Tools for Beginners
For those new to web scraping, selecting the right tools can make a significant difference in your experience and results. Tools like Octoparse and ParseHub are user-friendly and provide a visual interface for non-programmers. These platforms allow users to design their scraping workflows through simple point-and-click actions, enabling even those with minimal technical skills to efficiently scrape content online.
On the other hand, more advanced users may prefer programming-oriented solutions such as Python’s Scrapy framework. Scrapy not only offers extensive flexibility for data scraping, but also includes features for web crawling, data processing, and scheduling tasks. Knowing which web scraping tools fit your level of expertise and the specific requirements of your project is critical for a successful web data extraction.
When evaluating scraping tools, consider factors such as ease of use, support for various data formats, and integration capabilities with other software. Advanced tools often come with built-in features to handle issues like CAPTCHAs or dynamic content loading, significantly enhancing your ability to collect data from various types of websites. Investing time into learning the full capabilities of these tools can lead to more efficient scraping processes.
Furthermore, many scraping tools offer free trials or free subscription tiers, which allow you to test their functionality before committing. This is an excellent way to find the best solution for your specific scraping needs without unnecessary expenditure. Always read user reviews and explore tutorials before commencing with a scraping tool to ensure it aligns with your data extraction goals.
The Importance of Ethical Web Scraping
While web scraping can open up a wealth of data and information, it is imperative to approach the practice ethically. Understanding the legal boundaries and ethical implications of scraping websites is essential to conducting responsible data collection. Web scraping should always respect the terms of service of the websites being targeted to avoid legal repercussions and maintain a good reputation in the industry.
In addition to adhering to website rules, ethical web scraping includes being mindful of the volume of requests made to a site. Overloading a server with excessive scraping requests can result in website outages or damage to the infrastructure, which could disrupt service for legitimate users. Practicing responsible scraping not only helps maintain relationships with website owners but also supports overall internet health.
Furthermore, ethical concerns extend beyond just respecting legal boundaries. When scraping content online, it’s important to consider how the collected data will be used. Data privacy and protection laws, such as GDPR in the EU, dictate how organizations should handle personally identifiable information. Adhering to these regulations is critical to ensure that your data scraping practices don’t infringe on individuals’ rights.
By promoting ethical web scraping practices, data collectors can contribute positively to the online ecosystem. Establishing a code of conduct when it comes to data scraping will ensure that the community perceives this method as a valuable resource rather than a malicious activity. Hence, being ethical and responsible in web scraping not only governs successful data collection but also enhances the reputation of the industry.
Common Challenges in Web Data Extraction
Web data extraction can present a unique set of challenges that require careful consideration and strategic planning. One common challenge is dealing with websites that use dynamic content loading techniques, which can prevent traditional scraping methods from accessing the desired data. This often requires advanced scraping methods that include JavaScript rendering to navigate page elements effectively.
Another significant hurdle in web scraping is managing CAPTCHAs and anti-scraping measures that many sites have implemented to thwart unwanted data extraction. Overcoming these barriers typically involves employing specific techniques and tools designed to mimic human behavior or using rotating IP addresses to avoid detection. It is crucial to stay updated on the latest scraping tactics to address these obstacles effectively.
Additionally, the structure of websites can frequently change, impacting the scraping scripts and leading to broken or incomplete data extraction. This requires scrapers to have continuous maintenance and adjustments, which can be resource-intensive. Establishing monitoring tools that alert you to changes in website structure can help streamline this process.
Furthermore, ensuring data quality and accuracy after extraction is another vital aspect of web data scraping. This includes implementing validation processes to clean and verify the data collected against the source. Inaccurate data can lead to flawed analyses and conclusions, making data quality checks an essential step in any web scraping project.
Key Applications of Web Scraping
Web scraping has a wide range of applications across different industries, significantly impacting how businesses operate and make decisions. For instance, e-commerce platforms often utilize data scraping to monitor competitors’ pricing strategies and inventory levels. By analyzing this information, retailers can adjust their pricing models, optimize stock levels, and ultimately enhance their market competitiveness.
Another notable application of web scraping is in market research and sentiment analysis. Companies can gather customer reviews and feedback about their products or services from various platforms, enabling them to refine their offerings based on consumer preferences. By scraping social media data, businesses can gain insights into public sentiment and trends, allowing for more effective marketing strategies.
In the financial sector, web scraping is used to collect real-time data on stock prices, market news, and economic indicators. This information is crucial for traders and analysts who need to react quickly to market changes. By integrating web scraping into their analytics processes, financial institutions can make informed decisions that may impact their trading strategies.
Moreover, web scraping can serve as a valuable research tool for academic and scientific purposes. Researchers can pull data from various online databases, journals, and publications to analyze trends and compile comprehensive studies. By leveraging data scraping, scholars can save time in the research process and focus on critical analysis and interpretation of the results.
Best Practices for Effective Scraping Websites
To achieve successful web scraping results, adopting best practices is essential for optimizing the scraping process and ensuring data quality. First and foremost, always begin with a clear plan detailing specific scraping objectives and the kind of data you wish to extract. By defining your goals, you can streamline the scraping process and focus on acquiring the most relevant information.
Next, take the time to thoroughly understand the structure of the websites you intend to scrape. Familiarizing yourself with the HTML structure, CSS selectors, and the specific elements you want to access will enable you to write efficient scraping scripts. This foundational knowledge leads to smoother web data extraction and helps minimize potential errors during the scraping process.
Implementing error handling mechanisms in your scraping script is another crucial best practice. Websites may change their structure unexpectedly, leading to broken links or incorrect data retrieval. By including error handling features, you can make your scraping tool more resilient, allowing it to adapt to changes and continue functioning effectively.
Additionally, monitoring the performance of your scraping operation is vital for maintaining an efficient process. You can track metrics such as data retrieval time, server response, and volume of collected data. Conducting regular evaluations and optimizations will help you identify areas for improvement and ensure that you’re getting the most out of your web scraping efforts.
Legal Considerations for Web Scraping
When engaging in web scraping, understanding the legal landscape is critical for avoiding potential pitfalls. Websites may have terms of service that explicitly prohibit web scraping, which raises concerns regarding copyright infringement and unauthorized use of data. Before scraping a site, it’s advisable to review its legal stipulations to ensure compliance and protect against any legal repercussions.
Moreover, legal considerations extend beyond just the website’s terms. Data privacy laws, such as the General Data Protection Regulation (GDPR) in Europe, impose strict guidelines on how personal data should be collected, processed, and stored. Scraping personally identifiable information without proper consent could lead to severe penalties, so it’s crucial to ensure that your scraping activities align with relevant data protection regulations.
Additionally, ethical sourcing of data should be a priority for web scraping operations. Organizations must be transparent about data usage and respect the rights of individuals reflected in their data. Implementing best practices for data handling is essential not only for legal compliance but also for fostering trust with your data sources and users.
Keeping abreast of ongoing changes in laws related to web scraping is vital for businesses operating in this space. Legal frameworks may shift as new technologies emerge, and remaining informed will allow for proactive adjustments in scraping practices to ensure accountability and compliance.
The Future of Web Scraping
As technology continues to evolve, the future of web scraping holds exciting possibilities and advancements. With the rise of artificial intelligence and machine learning, scraping tools are becoming increasingly sophisticated. These innovations enable better data interpretation, allowing organizations to extract actionable insights quickly and efficiently, ultimately enhancing their competitive edge in the market.
Furthermore, as web data becomes more integral to decision-making processes, there will likely be a greater emphasis on data quality and ethical scraping practices. Businesses that prioritize sustainable and responsible data collection will likely lead the way in ensuring a balanced relationship with data sources and maintaining compliance with evolving regulations.
The continued growth of the Internet of Things (IoT) also influences the future of web scraping. As more devices connect to the web, there will be an increased volume of data available for collection. Scraping techniques are expected to adapt to these changes, allowing for the seamless extraction and processing of data from various sources, thus enriching analysis and reporting.
Overall, the future of web scraping promises to be characterized by innovation and improvement, shaping how data is obtained and utilized across industries. Organizations that embrace these advancements while adhering to ethical practices and legal guidelines will be best positioned to thrive amidst an increasingly data-driven landscape.
Frequently Asked Questions
What is web scraping and how does it work?
Web scraping is the automated process of extracting data from websites. It uses web scraping tools that fetch web pages, then parse the HTML content to retrieve specific information like text, images, or links. This technique facilitates web data extraction for various applications such as data analysis, market research, and content aggregation.
What are the best web scraping tools available?
There are several effective web scraping tools to choose from, including Beautiful Soup, Scrapy, and Selenium. These tools simplify the process of scraping websites and can handle complex web structures, enabling users to efficiently gather data online.
Is data scraping legal and ethical?
The legality of data scraping varies by jurisdiction and depends on the terms of service of the websites being scraped. Generally, while scraping public data may be permissible, it’s essential to review a website’s robots.txt file and terms of service to ensure compliance and ethics in web scraping.
What types of data can be collected through web data extraction?
Web data extraction allows users to collect various types of information, including product prices, reviews, event listings, and more. This data can then be used for analytics, business intelligence, or competitive analysis in various industries.
How can I automate scraping websites for content?
To automate scraping websites for content, you can use scripts written in languages like Python, employing libraries such as Requests and Beautiful Soup. Alternatively, web scraping tools like Octoparse or ParseHub provide user-friendly interfaces for non-coders to automate the scraping process.
What is the difference between web scraping and API data extraction?
While web scraping extracts data directly from web pages, API data extraction involves fetching information through a website’s application programming interface (API). APIs are typically more structured and reliable for data access, while scraping can retrieve data when APIs are not available.
Can I scrape content online without getting blocked?
Yes, you can scrape content online without getting blocked by employing techniques such as rotating user agents, using proxies, and implementing delays between requests. It’s also important to respect a website’s crawling policies outlined in its robots.txt file.
What are the common challenges faced in web scraping?
Common challenges in web scraping include handling website changes (which can break your scraper), managing anti-scraping measures like CAPTCHAs, and dealing with large volumes of data that need efficient processing and storage.
How can I handle dynamic websites using web scraping?
To scrape dynamic websites that use JavaScript for content rendering, tools such as Selenium or Puppeteer are effective. These tools can simulate a real browser environment, allowing you to capture content that may not be present in the initial HTML document.
What ethical considerations should I keep in mind when scraping websites?
When scraping websites, it’s crucial to respect copyright laws, adhere to the website’s terms of service, and avoid overloading servers with too many requests. Consider contacting website owners for permission if you’re unsure about the legality of your scraping activities.
| Key Point | Details |
|---|---|
| Content Access Limitations | External websites like wsj.com cannot be accessed or scraped directly. |
| User Input Requirement | Users must provide specific text or details for analysis or information. |
Summary
Web scraping is the process of extracting information from websites, but it is crucial to understand that direct access to certain sites can be restricted. In this case, content from external sites like wsj.com cannot be scraped without user involvement. Therefore, for effective web scraping, users should provide the necessary data or text they wish to analyze.











