
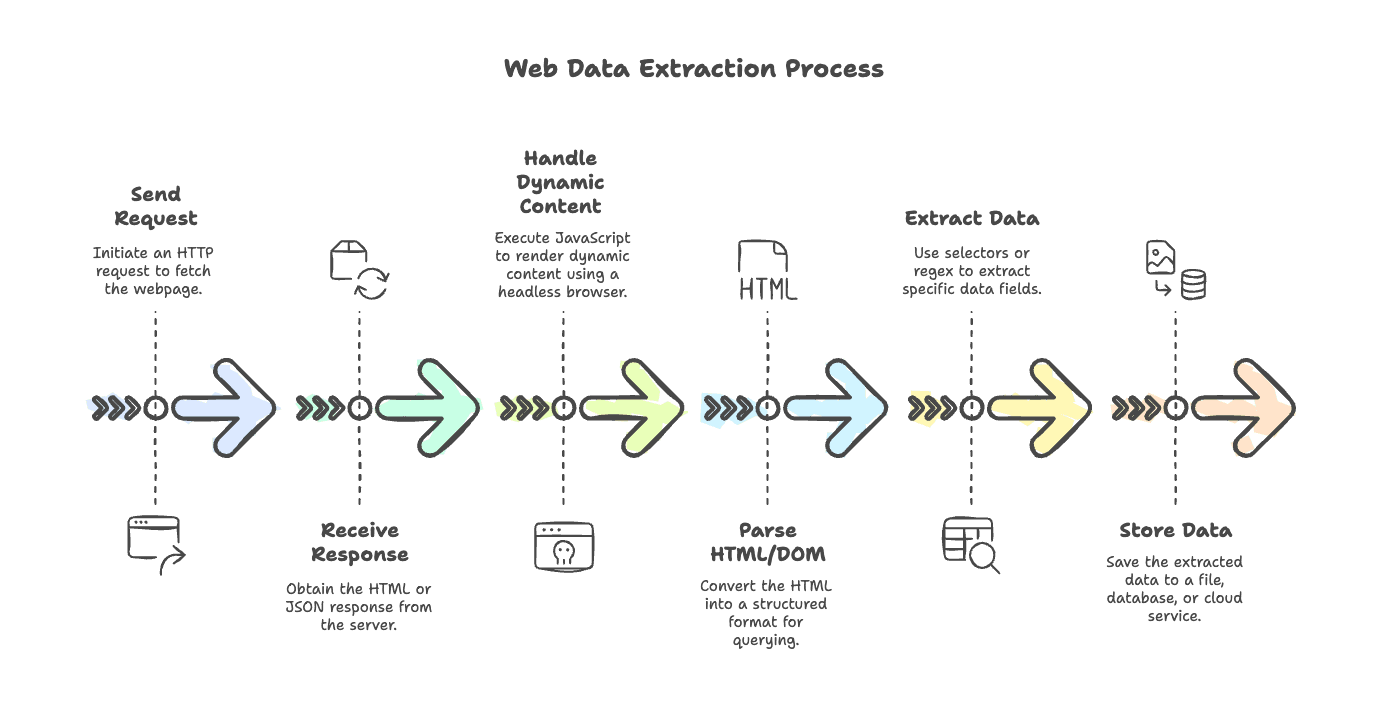
Web scraping techniques are essential tools for anyone looking to extract information from web pages effectively. With the rapid growth of online data, knowing how to harness these methods can empower you to gather valuable insights and streamline your research. Harnessing Python’s capabilities, particularly through the use of libraries like Beautiful Soup and requests, allows developers to navigate and scrape web content effortlessly. In this guide, we’ll explore various web data extraction methods that make the process seamless and efficient. Whether you’re a beginner or an expert, mastering these tools will enhance your approach to information technology and data analysis.
Understanding data extraction methodologies is increasingly critical in the digital landscape. Techniques for obtaining relevant information from websites, often referred to as web harvesting or data scraping, have gained popularity among developers and data enthusiasts alike. By leveraging programming languages such as Python, users can employ robust libraries designed for this purpose, allowing for simplified approaches to gather vast amounts of data. A Beautiful Soup tutorial can provide invaluable insights into structuring and navigating HTML content efficiently. In this web-centric era, grasping the fundamentals of these extraction strategies can significantly enhance your data-driven capabilities.
Understanding Web Scraping Techniques
Web scraping techniques encompass a variety of methods for extracting information from web pages. When done correctly, these techniques can provide a wealth of data from different online resources. One popular approach is to utilize libraries available in programming languages like Python, which has become a favorite among developers for its simplicity and efficiency. Key terms such as ‘web data extraction methods’ are critical in understanding how to effectively gather and utilize data from the internet.
In addition to the techniques, it is crucial to be aware of the ethical implications of web scraping. Adhering to the website’s terms of service and implementing polite scraping strategies ensures that you are compliant and respectful towards the data sources. Techniques may involve API usage or careful parsing of HTML, both vital components in modern web scraping.
Getting Started with Python for Web Scraping
Starting your web scraping journey with Python can be an exciting endeavor. Using Python for web scraping allows for rapid development of specific applications to gather data automatically. The two most essential libraries in this realm are Beautiful Soup and requests. Beautiful Soup offers a robust functionality for parsing HTML and XML documents, making it easier to navigate and search through the data you collect.
The requests library is another critical tool that simplifies the process of sending HTTP requests to retrieve web content. By utilizing these libraries together, you can create a powerful program capable of extracting essential information from web pages with minimal code. This combination of tools ensures that web scraping is not just easy but also efficient.
An Introduction to Beautiful Soup Tutorial
Beautiful Soup is a Python library that provides tools for web scraping. This library is especially beneficial for newcomers, as its straightforward methods allow users to navigate HTML trees easily, facilitating the extraction of data. In a Beautiful Soup tutorial, learners will often start by installing the library using pip, creating a fundamental understanding of how to fetch and process web pages.
Once you have Beautiful Soup set up, the next step is to learn how to parse HTML content effectively. You will explore commands that can help you locate specific tags, attributes, and text within web pages. This parsing capability is crucial, as it directly supports the goal of extracting valuable information for data analysis and other applications.
Using the Requests Library for Python
The requests library in Python is an essential tool used for web scraping, designed to make HTTP requests simpler and more user-friendly. By using requests, developers can easily obtain HTML content from any URL. The basic functionality includes methods such as GET and POST, which are fundamental to interact with web servers, allowing the retrieval of web pages that contain the data needed for scraping.
An integral part of the scraping process is handling the data received from requests. After retrieving the HTML content, the next step typically involves passing this content to Beautiful Soup for further processing. Understanding how to effectively use the requests library alongside Beautiful Soup will greatly enhance your web scraping capabilities.
Key Web Data Extraction Methods
There are several web data extraction methods that developers can deploy based on their specific needs. One common approach involves static web scraping, where the HTML structure of a web page remains mostly unchanged. In this scenario, tools like Beautiful Soup work effectively by identifying the required tags and extracting information directly.
Dynamic web scraping, on the other hand, involves pages that load content asynchronously with JavaScript. For such scenarios, libraries like Selenium or Scrapy may be necessary to ensure complete data retrieval. Understanding the distinction between these methods is crucial for selecting the best approach for any data extraction project.
Best Practices for Ethical Web Scraping
In today’s digital landscape, ethical web scraping practices must be prioritized to maintain the integrity of data collection. This includes adhering to the guidelines set by websites, such as the robots.txt file, which outlines allowed scraping behavior and indicates which sections of a site should not be accessed by automated tools.
Furthermore, implementing delay and frequency limits in your scraping scripts helps prevent overwhelming servers, ensuring that your actions remain courteous. By practicing ethical web scraping, you contribute positively to the broader web scraping community and build trust with the website owners from which you are extracting data.
Challenges and Solutions in Web Scraping
Web scraping is not without its challenges, as many websites employ anti-scraping techniques to block automated data extraction. These can include CAPTCHAs, dynamic content loading, and rate limiting. Understanding these challenges is pivotal for anyone looking to successfully scrape websites.
Fortunately, there are solutions to navigate these hurdles. For instance, utilizing headless browsers for rendering JavaScript or implementing proxy servers can help in bypassing some of these barriers. Additionally, improving your scraping speed and efficiency through optimized code minimizes the risk of being detected and blocked.
The Importance of Data Cleaning after Scraping
Once you have successfully scraped data from web pages, the next crucial step is data cleaning. Raw data often comes with inconsistencies, duplicates, and irrelevant information that can skew analysis. By utilizing various data cleaning techniques, such as removing duplicates and filling missing values, you ensure that the data is ready for use.
Data cleaning not only improves the quality of your dataset but also enhances the accuracy of insights drawn from analysis. Using Python libraries like Pandas can streamline this process, allowing for efficient manipulation and organization of your scraped data. Proper data cleaning is essential for turning chaotic web data into reliable information.
Advanced Techniques for Web Data Extraction
For those who have mastered the basics of web scraping, advanced techniques can elevate data extraction projects to new heights. Some of these techniques include password-protected scraping, where users must log in to access data. This involves managing session cookies and handling user authentication securely.
Another advanced method includes parallel scraping, where multiple threads or processes are utilized to scrape data from several sources simultaneously. This can significantly increase the speed of your data collection process and is especially useful when dealing with a large volume of information.
Frequently Asked Questions
What are the best web scraping techniques for extracting information from web pages?
The best web scraping techniques for extracting information from web pages include utilizing libraries like Beautiful Soup and requests in Python. These tools allow you to parse HTML content and efficiently retrieve data such as text, links, and images. Additionally, employing methods like XPath or CSS selectors can enhance your data extraction capabilities.
How can I use Python for web scraping effectively?
To use Python for web scraping effectively, start by installing essential libraries such as requests for fetching web pages and Beautiful Soup for parsing HTML. Combine these tools to send a request to a webpage, retrieve its content, and extract relevant data. Familiarizing yourself with web scraping methods will streamline your process.
What is a Beautiful Soup tutorial for beginners in web scraping?
A Beautiful Soup tutorial for beginners typically covers how to install the library, make an HTTP request using requests, and parse the HTML returned. It teaches you how to navigate the parsed tree structure and extract desired elements using methods like find() and select(). This is foundational for mastering web scraping techniques.
How do I use the requests library for Python web scraping?
To use the requests library for Python web scraping, first install it via pip, then import it in your script. Use the requests.get() method to retrieve the HTML content of a webpage. After obtaining the content, you can further process it with Beautiful Soup or other parsing libraries to extract valuable information.
What are some effective web data extraction methods?
Effective web data extraction methods include HTML parsing with Beautiful Soup, API requests where available, and utilizing browser automation tools like Selenium for dynamic content. Each method has its strengths, and understanding when to use them can optimize your web scraping techniques for maximum efficiency.
| Key Point | Description |
|---|---|
| Web Scraping Limitations | The assistant cannot directly scrape web pages or access current online content. |
| Tools for Web Scraping | Python is recommended for web scraping tasks, utilizing libraries like Beautiful Soup and requests. |
| HTML Extraction Assistance | The assistant can help extract specific elements from provided HTML content. |
Summary
Web scraping techniques are essential for extracting information from websites effectively. This process often starts with understanding the limitations of scraping, especially the inability to access live webpages directly. To overcome this, tools such as Python’s Beautiful Soup and requests libraries are commonly employed for their robust functionalities. By mastering these techniques, one can efficiently gather and manipulate data from web pages, enhancing both data analysis and business intelligence efforts.











